ClaudeOS: How I Learned to Stop Worrying and Love the Slop
A reflection on the current abilities of agentic coding. Story of vibecoding a functioning OS that can play DOOM, in TWO DAYS.
On 6th of February, I saw a post from Anthropic, sharing their upcoming virtual hackathon starting in 10th and lasting one week. After some thought, on the 7th I decided to apply/register to try my luck. You register by answering bunch of questions asked by an LLM. Towards the laters stages, the model asked me "For this hackathon, what would you like to build?". This was my first hackathon to be, and I did not have a specific idea on my mind, I thought you were supposed to figure that out during the event. I asked ,somewhat jokingly, "do i need to decide now" and it basically said, in a kind LLM way, that yes I did. After some exploring and discussion with Claude, I put forward the idea of building an OS from scratch, inspired by the recently viral C compiler written in Claude Code autonomously. Claude did warn me that it was a very ambitious project but after some back and forth it reluctantly agreed that I should attempt it nevertheless. I picked a monitor personalization app as a backup project if the OS idea was too much to handle. After few more small details, the registering process was done.
On the 8th, I decided to do some "training runs" with the aim of seeing how this could be done if it could be done at all. At this stage of my life, I do not know many good CS people apart from my proffessors, so my only frame of reference about how hard this task would be are LLMs, and we know that LLMs are really outdated on these types of guesses but even so, they were convincing enough that I thought this would be a very hard project, lasting the full week, so starting early to see what lays ahead seemed like a good idea. I had heard of OSDev from the LLMs who suggested me to read some of the basic documents on there before starting. I, of course, did not read any of them but instead, found an XML dump of the whole website and decided to create a local library of the webpages. I let Claude build up a phase and task oriented roadmap, then asked Codex to create a script that will take the dump and create individual markdowns for each page then curate it to create a folder where the relevant documents to the scope of the project and roadmap were included. So there was a whole library which included the whole OSDev wiki, and also a "core" folder where the most relevant documents were copied to be used as reference points by the agents. Roadmap included 7 phases and 34 tasks in total. After creating a proper AGENTS.md (and CLAUDE.MD, compliments of Anthropic), repo was ready to go. I also asked the agents to log what they were doing on a document called "PROGRESS.md" which now serves basically as the court historian of the project.
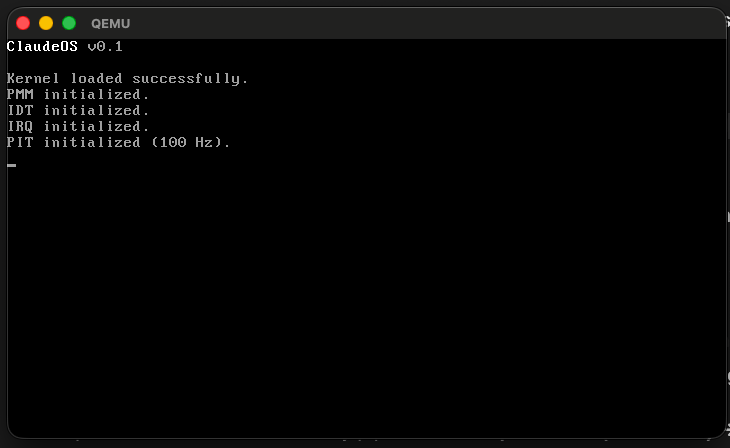
I started with a three-agent setup on Claude Code: one agent writes code, another reviews it for bugs, and a third orchestrates between them. The idea was that this careful approach would catch issues early before they compound. I kicked off Task 1 (writing the MBR bootloader) and went to play some blitz chess on a second monitor. Five minutes later, the agent pinged me: Task 1 done. The bootloader was booting in QEMU, and the reviewer had caught a small bug which gave me some small confidence about the setup. Task 2, Task 3, same story. Each one landing relatively clean in minutes. I prompted "yes continue" and continued playing chess. Phase 1, the entire boot sequence from MBR to a C kernel with VGA output, was done in under an hour.
One problem was that this careful setup was expensive. Claude on the $20 subscription has brutal rate limits, and the three-agent pattern was eating through my credits fast, around $3-5 per task. I had about $40-50 from the new Opus 4.6 Fast promotion, and it was draining quickly. By the time I hit Phase 2 (memory management and paging), I was running low. I could have just stopped and waited for the hackathon to start, where I would be getting $500 in API credits if selected, but I wanted to continue anyway. The current phase was supposed to be one of the hardest parts, where LLMs predicted the most friction would lay.
It worked on the first try. The higher-half kernel remap, recursive page directory mapping, all implemented relatively painlessly. I ran a manual audit between phases and while nothing was broken in the moment, the audit caught some issues that apparently would've been nightmares later. At that point I was out of credits, so I pivoted to Codex. No more three-agent setup, just one agent and me, with manual audits between phases in a different window. Ironically, running a single Codex instance was faster than the three agent Opus setup even though Codex is notoriously slower than Opus normally. I wasn't too happy about the reviewer setup being ruined but manual auditing would have to do. Claude in a web instance was basically my orchestrator at this point, telling me which issues the audit identified were worth paying attention to and which ones to skip.
I also went away for a long time, touching some
grass, before coming back at night. I worked for
a few more hours, I already had a working
text-mode OS. Bootloader, kernel, interrupts,
memory management, a preemptive scheduler,
keyboard input, and a console. I could type
commands and see output. The next big test was
user mode: getting the OS to enforce privilege
separation between kernel (ring 0) and userspace
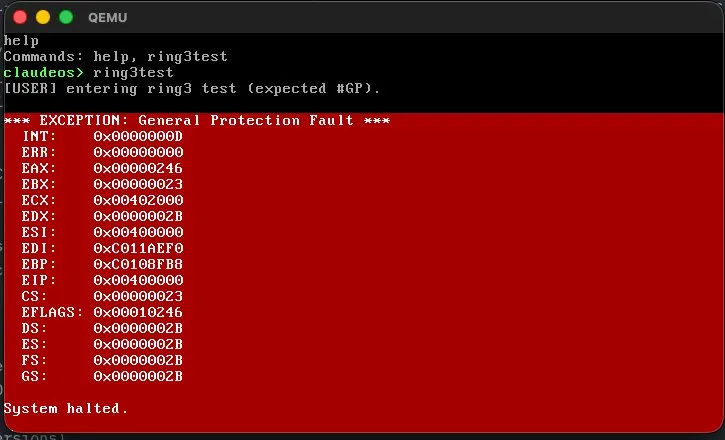
(ring 3). Codex basically added a test command
called ring3test that deliberately
tries to execute a privileged instruction in
user mode. If it faults, the transition worked.
I typed the command and got a General Protection
Fault. The CPU was enforcing privilege levels on
code written entirely by AI agents. After
completing that task, I went to sleep around 3
AM.
On the afternoon of February 10th, I got the rejection email from the hackathon. "We received an incredible number of applications, far more than the 500 spots we had available." By that point I already had a working OS with syscalls, an ELF loader, a VFS with both initrd and FAT32 support, and userspace programs running in ring 3. The hackathon would've been nice for the API prize money but I mainly wanted the opportunity to actually talk to important people. By this point all my cold emails have been ignored so I was looking for a way to have an actual conversation with someone who might want to give me a chance. Rejection stung a bit but it is what it is and I'm used to it, its still a good personal project and there was no point in stopping now.
Next up was the GUI. Twenty-four hours earlier, adding a graphical desktop would've been "insane scope creep", according to Claude. But at this point, it felt inevitable. VESA framebuffer mode, pixel drawing primitives, font rendering, a window manager with draggable title bars went into the roadmap. A few hours later I had a desktop with empty windows named System Monitor, Files, and Task Log. Later I added stuff like calculator and terminal for a more realistic desktop experience. The mouse was working (PS/2 driver) and it felt like I was using a 10hz monitor. Still, it was 0 to GUI in a day, I cant complain.
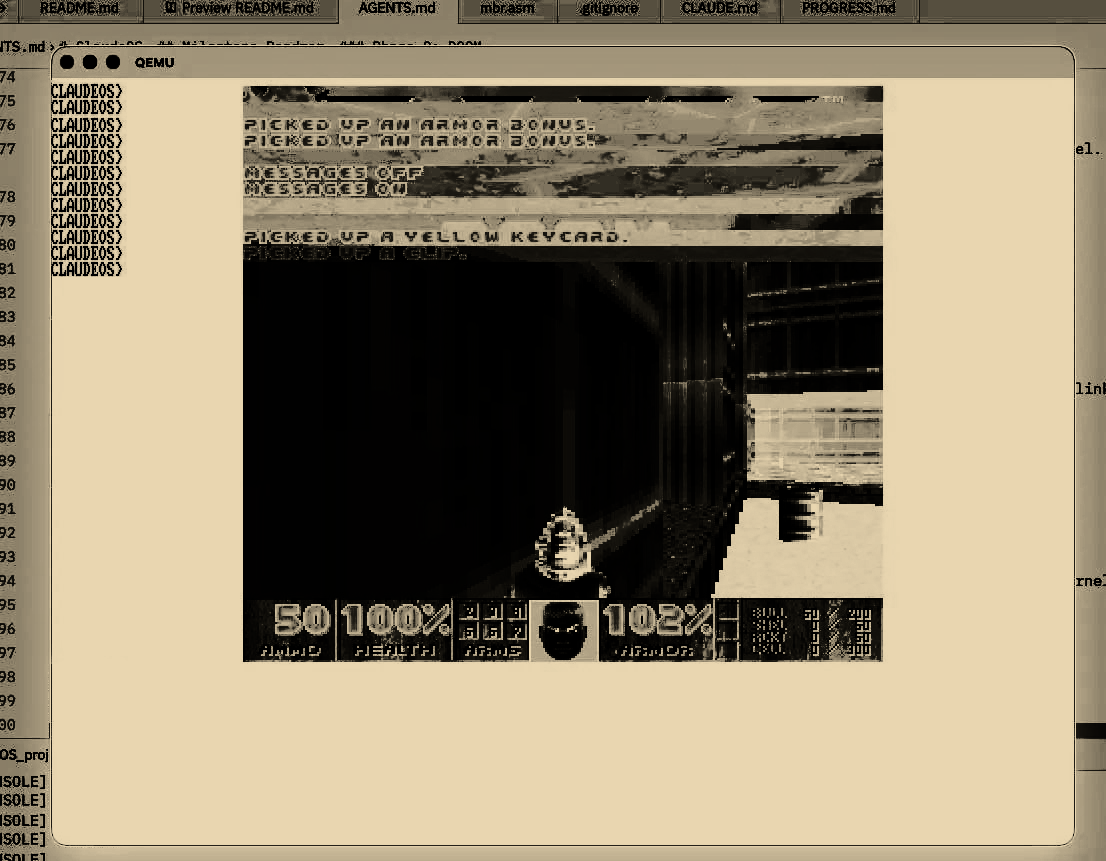
The next phase was DOOM. The ultimate test. It's a really good benchmark, everyone has a spot in their mind for the abstraction of running DOOM on things, it maps to something. Claude recommended to use doomgeneric, a minimal DOOM port designed to be portable. You just implement five platform functions (framebuffer draw, get ticks, get keys, sleep, init) and it runs. The libc needed expanding, the heap needed to support 16MB+ allocations for DOOM's memory requirements, and the build system needed to compile and link the DOOM source as a userspace ELF binary.
This was the first time I hit real friction. The
kernel image got too big for the bootloader's
hardcoded sector count (a bug that had been
flagged in earlier audits but deferred). DOOM
was reading the -iwad argument from
the wrong argv slot. Then it got stuck loading
the WAD file. Turned out reading a 4MB file
manually was painfully slow. This was basically
the only real troubleshooting I had to do
instead of prompting "good job, next task" . But
even with that, DOOM was rendering frames within
an hour or so. I tried WASD first and was
prepared to tell Codex that the keyboard wasnt
working in DOOM before realizing it's arrow
keys, and suddenly I was picking up armor
bonuses and walking through corridors on an OS
that didn't exist 72 hours earlier.
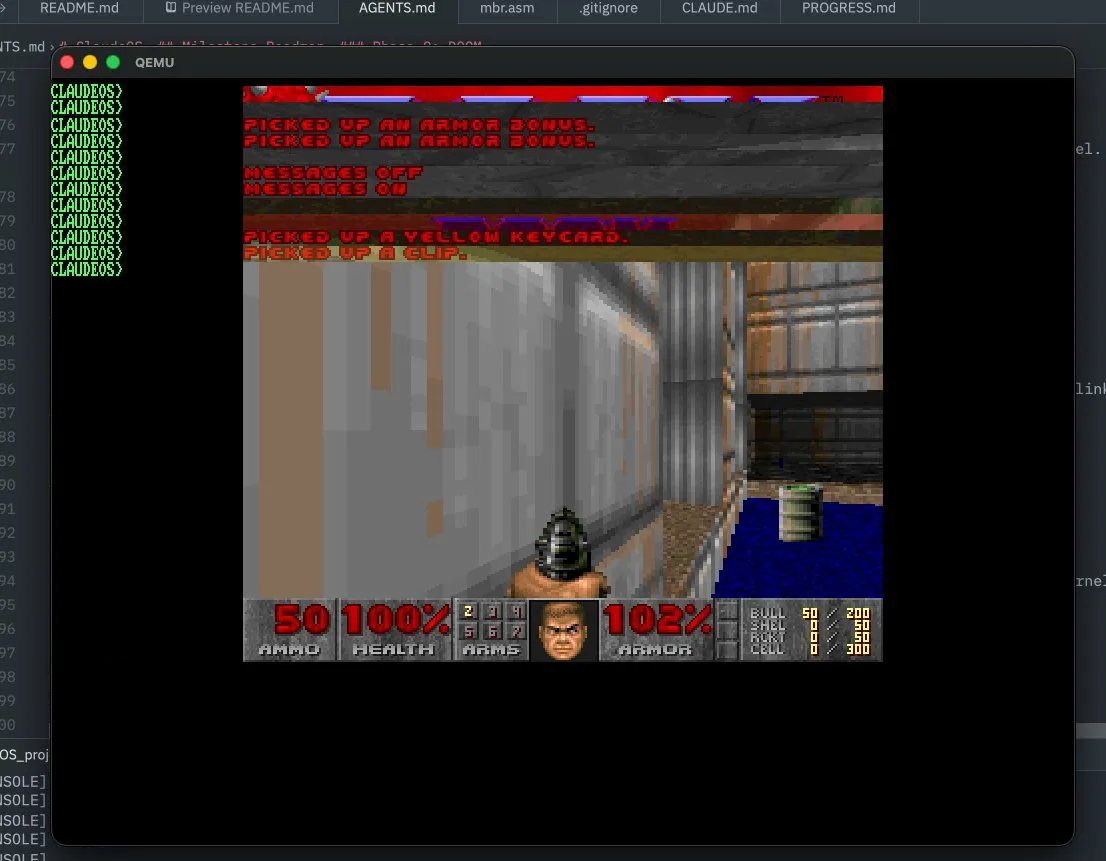
From an empty directory to DOOM running on a custom OS with a GUI desktop, the whole thing took about less than three days of casual prompting inbetween tasks. I did not write a single line of code. Not one. The agents worked off of curated OSDev wiki documents, a structured roadmap, and periodic bug audits that I ran between phases to catch issues before they compounded. The documentation approach should probably get the 6th man award. this is probably not possible without OSDev wiki, not at this pace anyway.
I do not know how to code an OS, in fact I do not know the name of most of the things that an OS depends on. I am barely competent enough on C++ and I mainly use Python. So in some terms, the tech debt in this project is so great that I am not sure about the sheer complexity of the thing "I" have created. It might be pure slop, it might be a good starting point (likely the former) and I wouldn't know. But taking a step back, that alone is an insane sentence on its own. No matter how bad, how unfunctioning and how much spaghetti, somebody who has no experience in low-level development simply could not even fathom the idea of creating their own OS from scratch in months let alone days, thats what the LLMs tell me anyway. There is a slight irony in the tech debt of not knowing how much tech debt you have.
I saw a lot of people commenting about the C compiler that Claude wrote. Many were impressed, many were indifferent and many were quite critical. The main criticisms of it were that a) it wasn't "a true compiler but a hardcoded spaghetti mess" and b) it "had seen a lot of compilers in its training data and of course it would be able to imitate that". I think the first one is somewhat valid, seeing how many issues it had but the second one is definitely not and both are massively missing the point. We are at a stage where the tasks only the truly best would be able to do on their own are now can be done poorly by anyone. The implication of this is that anyone who is knowledge enough can get so much acceleration TODAY that its not even funny. And by few years, what I did today will be able to be reproduced by anyone without any real programming knowledge if they cared enough. A lot of programmers havent realized this, and the market certainly has not. We are still in a bubble in terms of LLMs in the context of awareness, a lot of programmers who are much better and knowledgeable than me probably can't do what I achieved in these last days because they are simply not aware. But when the awareness bubble pops, or slowly diffuses into all the developers, there is no turning back for both software engineering and probably the world. I find it hard to believe that the software engineering market for jobs will not shrink in noticable ways in the next decade. While software is the first one, it certainly wont be the last one and there is also a possibility these shrinking jobs might not be a net shrinking on global jobs. Obviously, current landscape creates a lot of uncertainty and questions for the future, but it has never been relatively simple to guess the unknown. I dont know whether this will have good implications for me as a CS sophomore and more broadly the world, but I am not too pessimistic about it.
What I do know is this: the gap between what one person can produce and what one person can understand has never been wider. A sophomore who mainly writes Python now has a functioning x86 operating system with privilege separation, a filesystem, a GUI, and DOOM built in few days. That sentence would have been absurd basically at any time point but 2026 and we are still accelerating. The greater point is that, just as well as widening it, AI might allow for this gap to not matter at all. Overwhelming majority of SWEs wouldnt know how their compiler works, that doesnt stop them from using it. If we get to the competence level where LLMs are even close to being trustable as compilers, the tech debt will not matter at all. Only thing standing between you and a good idea will be (and arguably already is) your imagination, not the implementation.